EDIT May 29th 2009: The code presented in this post has a major bug in the calculation of inverse DFTs using the FFT algorithm. Some explanation can be found here, and fixed code can be found here.
Once the DFT has been introduced, it is time to start computing it efficiently. Focusing on the direct transform,

if the size of the input is even, we can write N = 2·M and it is possible to split the N element summation in the previous formula into two M element ones, one over n = 2·m, another over n = 2·m + 1. By doing so, after some cancellations in the exponents we arrive at
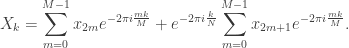
There’s something very promising here: each of the two summations are very close to being the expression of a DFT of half the size of the original. The only thing preventing them from fully being so is the fact that k runs from 0 to N-1, rather than up to M-1 only. To get around this, we will consider two different cases: k < M and k ≥ M. The first trivially produces a pair of half sized DFTs, which we will term Ek and Ok, owing to one running over the even indexes, the other over the odd ones:
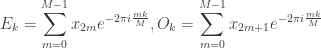
As for the case k ≥ M, we may as well write it out as k = M + k’. And if we plug this value into the original formula, work a little with the algebra, and then undo the variable change, i.e. plug k’ = M – k back in, we arrive at the following combined formula,

The cool thing about this decomposition is that we have turned our N element DFT into two N/2 DFTs, plus some overhead composing the results, which includes calculating twiddle factors, i.e. the complex exponential multiplying the O’s in the last formula. Given the quadratic nature of the time required to calculate the DFT, this amounts to cutting the time in half. And the best part is that we need not stop after one such decomposition: if the original size is a power of two, we can keep doing the same trick recursively until we reach a DFT of only two elements, for which we already have produced explicit formulas. A similar approach can be used for the inverse DFT, the details are built into the following code…
from __future__ import division
import math
import time
def fft_CT(x, inverse = False, verbose = False) :
"""
Computes the DFT of x using Cooley-Tukey's FFT algorithm.
"""
t = time.clock()
N = len(x)
inv = -1 if not inverse else 1
if N % 2 :
return dft(x, inverse, False)
x_e = x[::2]
x_o = x[1::2]
X_e = fft_CT(x_e, inverse, False)
X_o = fft_CT(x_o, inverse, False)
X = []
M = N // 2
for k in range(M) :
X += [X_e[k] + X_o[k] * math.e ** (inv * 2j * math.pi * k / N)]
for k in range(M,N) :
X += [X_e[k-M] - X_o[k-M] * math.e ** (inv * 2j * math.pi * (k-M) / N)]
if inverse :
X = [j/2 for j in X]
t = time.clock() - t
if verbose :
print "Computed","an inverse" if inverse else "a","CT FFT of size",N,
print "in",t,"sec."
return X
The speed gain with this approach, restricted for now to power of two sizes, are tremendous even for moderately large input sizes. Mostly so due to the fact the new algorithm scales as N log N. For instance, a 220 (~106) item input can be processed with the FFT approach in a couple of minutes, while the projected duration using the naive DFT will be more like a couple of weeks…
Twiddle Factors Again
While it may not be immediately obvious, the previous code is generously wasting resources by calculating over and over again the same twiddle factors. Imagine, for instance, a 1024 element DFT computed using this algorithm. At some point in the recursion the original DFT will have been exploded into 64 DFTs of 16 elements each. Each of this 64 DFTs must then be composed with the exact same 8 different twiddle factors, but right now they are being calculated from scratch each of the 64 times. Furthermore, half of this 8 different twiddle factors are the same that where needed to compose the 128 DFTs of 8 elements into the 64 DFTs of 16 elements… Summing it all up, to compute a FFT of size 2n, which requires the calculation of 2n-1 different twiddle factors, we are calculating as many as n·2n-1 of them.
We can easily work around this by precalculating them first, and then passing the list to other functions. For instance as follows…
def fft_CT_twiddles(x, inverse = False, verbose = False, twiddles = None) :
"""
Computes the DFT of x using Cooley-Tukey's FFT algorithm. Twiddle factors
are precalculated in the first function call, then passed down recursively.
"""
t = time.clock()
N = len(x)
inv = -1 if not inverse else 1
if N % 2 :
return dft(x, inverse, False)
M = N // 2
if not twiddles :
twiddles = [math.e**(inv*2j*math.pi*k/N) for k in xrange(M)]+[N]
x_e = x[::2]
x_o = x[1::2]
X_e = fft_CT_twiddles(x_e, inverse, False, twiddles)
X_o = fft_CT_twiddles(x_o, inverse, False, twiddles)
X = []
for k in range(M) :
X += [X_e[k] + X_o[k] * twiddles[k * twiddles[-1] // N]]
for k in range(M,N) :
X += [X_e[k-M] - X_o[k-M] * twiddles[(k - M) * twiddles[-1] // N]]
if inverse :
X = [j/2 for j in X]
t = time.clock() - t
if verbose :
print "Computed","an inverse" if inverse else "a","CT FFT of size",N,
print "in",t,"sec."
return X
This additional optimization does not improve the time scaling of the algorithm, but reduces the calculation time to about two thirds of the original one.


What about in C
for
DFT
fourier transform of bessel function using FFT
If you don’t want to go through the hassle of porting this code to C, I’d suggest using the best freely available FFT library, which happens to be native C: FFTW
Thanks for your lucid explanation, Jaime!
I have a couple of questions. I’m not very familiar with DFT, so pardon me if my questions are simple-minded.
The procedure, as you described, works in n*log(n) time only for even n (really, power-of-2). The wikipedia article mentions that a similar thing is possible for any n=n_1*n_2, but nothing about the extending the “binary” idea above immediately to odd n (without factoring). Do you know if that can be easily done? I ask this only out of curiosity. (Since we’re anyway doing ~ n*log(n) time, so asymptotically, we might as well go ahead and try and factor n.)
The second question is kind of related: In FFT applications, is it usually the case that there is some leeway in choosing n, so that it can be comfortably be taken as a power-of-2?
As far as I know, factorization is the only way to do the FFT trick. I have a post about to come out of the oven on the generalized Cooley-Tukey algorithm, which does the factorization trick for factors other than 2, stay tuned!
As of real world applications… In signal processing what you are normally after is the spectrum of a continuous signal, but the DFT is applied to a signal which has undergone windowing, i.e. it has been clipped in time, and sampling, i.e. discretized.
These manipulations produce, respectively, spectral leakage and aliasing, which distort the result obtained from what you would really want to have: a sampling of the continuous Fourier transform of the input signal. This wikipedia article works out the math, if you are really interested.
The point is that, since what you are going to get is only an approximation of the real thing, there really shouldn’t be much problem in having a number of samples which is a power of two: even if you are interested in a very particular frequency, it is going to get mixed up with nearby ones, so you don’t need to hit the right value.
On the other hand, the FFT can also be used, and I do it all the time at work, to compute efficiently cross-correlations and convolutions of discrete functions, images in my case, via the cross correlation or convolution theorems. Although it could be possible (I think…), through zero padding, to still only work with power of two sizes, that would be very inconvenient, and general sized DFTs are computed all the time.
So I guess the answer is: it depends…
Much thanks for that detailed references.
You write beautifully. I was just studying your post on divisors — very interesting.
Perhaps you have it too in the oven, but how about a post on some applications of FFT too — say, around some of the image processing stuff you mentioned?
Excuse me, why does this line
X += [X_e[k-M] – X_o[k-M] * twiddles[(k – M) * twiddles[-1] // N]]
(present also in the correct code) do multiply by N and then divide by N?
I’m a bit confused about the math. In the DFT formulas X[k] represents the frequency content in the k-th bin and x[n] is n-th sample in the time domain. Then n is substituted for 2m and 2m+1 and there is the problem of k going from 0 to N-1. Why is that a problem if we’re looking for X[k] ? Isn’t k supposed to be a constant for each sum? Sorry if I’m not making sense 🙂
Haha, silly me. No need to answer the question, I get it. You can remove both of the comments 😉
What module is the dft method defined in. It seems the code is incomplete at line 13.
Very nice post. I just stumbled upon your blog and wished to
say that I’ve truly enjoyed browsing your blog posts. After all I’ll be subscribing to
your feed and I hope you write again very soon!